HD 5514 Research Methods (Fall 2019)
Inference for Means (T-Test) (W12)
HD 5514 Research Methods (Fall 2019)
- In-Class Acitivity: One-Sample T-Test
- In-Class Acitivity: Two-Sample T-Test
- Assignment 8 (Week 12)
- Read Data
- Check Data
- Use the help function to learn about variables
- Check two data frame columns (group, extra)
- Conduct the unpaired t-test between two populations means (Welch t-test by default)
- Conduct the unpaired t-test between two populations means (Student’s t-test)
- FYI: Test equal variance using Bartlett’s test
- FYI: Visualize your data using a box plot by group
- FYI: Conduct the paired t-test
In-Class Acitivity: One-Sample T-Test
Load Data
We are going to use mtcars data included in R by default. We will load and print the mtcars data.
Print Data
We can view the content of the mtcars data.
Check Data Set
Check the number of rows and columns.
# Display the internal structure of an R object.
str(mtcars)
# Check the dimension of an object
dim(mtcars)
# Number of rows (observations)
nrow(mtcars)
# Number of columns (variables)
ncol(mtcars)If you want to learn more about the mtcars data set, you can bring up a helpful file for functions and datsets.
Check the data frame column (mpg)
First, find the data column, named mpg (gas mileage) of the mtcars data set.
Visualize your data using a box plot
First, find the data column, named mpg (gas mileage) of the mtcars data set.
Compute one-sample t-test (two.sided)
Use the t.test() function to perfom one-sample t-test (two.sided)
Compute one-sample t-test (one.sided)
Using the alternative argument to change the alternative hypothesis. alternative argument allows one of the following options: “two.sided” (default), “greater” or “less”.
Compute one-sample t-test with a different mean
Using the mu argument to change the theoretical mean. Default is 18 but you can change it (mu = 20).
Use the help function
If you want to learn more about the t.test function.
In-Class Acitivity: Two-Sample T-Test
Check two data frame columns (mpg, am)
If two samples come from unrelated populations, they are independent.
First, find the data column, named mpg (gas mileage) of the mtcars data set.
# Print the mpg column
mtcars$mpg
# Create a freqeuncy table for the mpg column
table(mtcars$mpg)
# Compute mean
mean(mtcars$mpg)
# Compute standard deviation
sd(mtcars$mpg)Next, find another data column, named am (transmission type; 0 = automatic, 1 = manual) in the mtcars data set.
Conduct the unpaired t-test between two populations means
If two samples come from unrelated populations, they are independent. Compute the difference in means of the two sample data using the t.test fuction
Assignment 8 (Week 12)
Read Data
We will use build-in data set sleep. We will load and print the survey data.
Check Data
Check the number of rows and columns.
Use the help function to learn about variables
If you want to learn more about the t.test function.
Check two data frame columns (group, extra)
First, find the data column, named extra, of the survey data set.
Next, find another data column, named group in the survey data set.
Conduct the unpaired t-test between two populations means (Welch t-test by default)
Compute the difference in means of the two sample data using the t.test fuction. By default, t.test does not assume equal variances; instead of Student’s t-test, it uses the Welch t-test by default.
Conduct the unpaired t-test between two populations means (Student’s t-test)
Now, assume equal variance and use Student’s t-test by setting var.equal=TRUE.
FYI: Test equal variance using Bartlett’s test
You can test whether two or more samples are drawn from populations with “equal variance” using Bartlett’s test. The null hypothesis of this test is that the variances are equal. The alterntive hypothesis is that they are not equal. If you fail to reject the null hypothesis, that means there is not enough evidence to suggest that the variance is different for groups. Thus, you can assume equal variance.
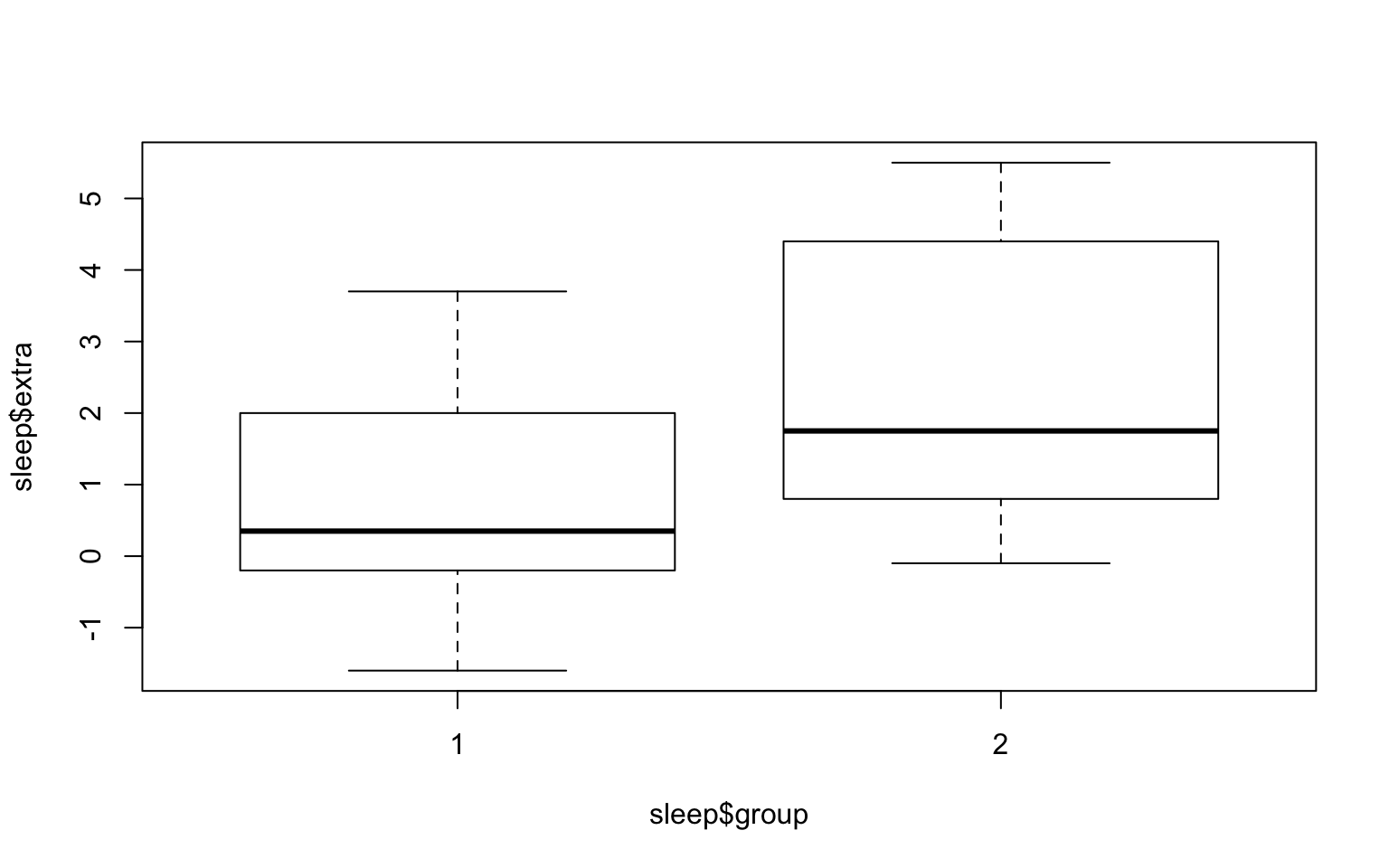
FYI: Visualize your data using a box plot by group
You can visualize both groups (1 and 2) using the boxplot function.
FYI: Conduct the paired t-test
When each subject is measured twice such as repeated-measures designs, it will result in pairs of observations that are not independent. In this case, we analyze the differences before and after using a paird sample t-test. We will test whether the mean values for the extra variable differs by the group variable to look at the difference between the two groups (group 1 and group 2).
Paired t-test
data: extra by group
t = -4.0621, df = 9, p-value = 0.002833
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.4598858 -0.7001142
sample estimates:
mean of the differences
-1.58